What we've learned from talking to 500+ Product Managers
What we've learned from talking to 500+ Product Managers


Our History
Dwayne Samuels and myself Shawn McLean, co-founded Samelogic because, throughout our 14+ years in the tech industry, we keep seeing ourselves and others waste money and time building products and features nobody wants.
Throughout our time in various organizations such as Draper University, where Dwayne advised startups, and myself working in mid-end stage startups such as Auth0 as a product engineer, we still didn't learn how to build products right.
We followed what the "agile" or "lean" folks had to say. "You must talk to users," they said. "Product Discovery is King," they told us.
We've seen many processes being used to tighten the feedback loop between what the user says they want and what they say after using the product.
These #agile #lean #scrum processes and the 10 different frameworks being pushed onto teams don't work, they are a scam. They will measure velocity, lead time, cycle time, lines of code written, and all sorts of vanity metrics sold to them by consultants or authors of books whose experiences are completely different from their team and business.
But blindly adopting and following processes someone else made up is the least of the problems facing product teams.
Teams were still building the wrong things in these frameworks. They keep chasing what users tell them to do.
Humans Lie
One thing we've learned for certain after working in these companies is that humans lie. It's not always on purpose, so we must rely on the scientific method and reasoning to straighten things out.
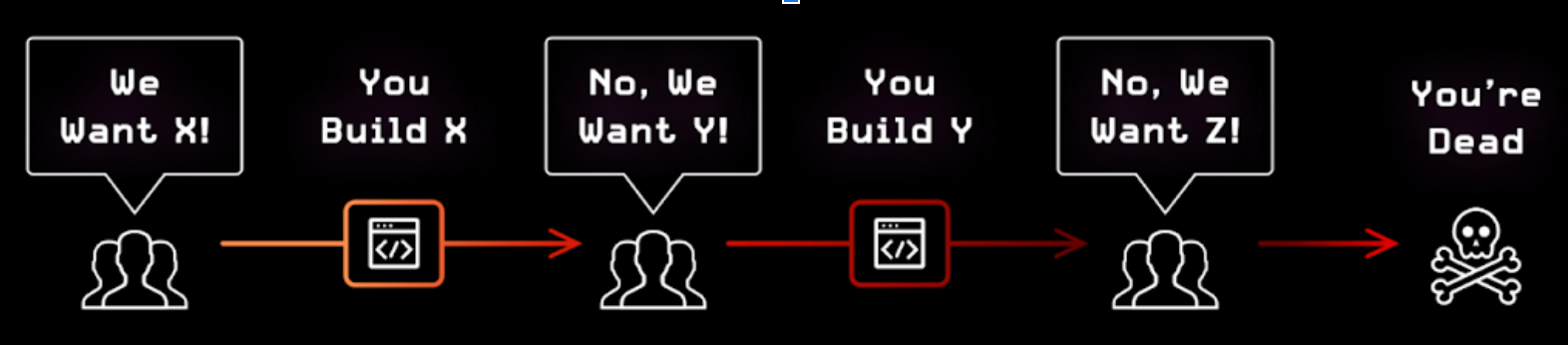
The Agile Manifesto or the "leanness" cannot help in this case; your $1m DevOps pipeline is just helping you to ship the wrong things faster. If the people at the front do not come in with good information, then we will build nonsense. Garbage in, garbage out.
Product Managers, Project Managers, Product Owners, Scrum Masters, Business Analysts, User Experience Researchers, and CEOs are just some names given to the people at the front.
They consistently come back with the knowledge that leads to a dead end. This is no fault of theirs but the fault of the process and methods, as you'll learn by the end of this article.
Second-hand information or Chinese Whispers is also a real but unknown issue on product teams. All engineers should talk to their users, regardless of company size. The builders should not be so abstracted from the real world.
So how do we talk to users and remove as much bias as possible? A big part of human communication is body language, as much as 66%. We are missing nearly half of the human experience if we're not talking to them in person. An even larger role is played by facial expressions correlating to lies.
😌 Chasing Emotions
A few years ago, we decided to test out the idea that we can get more accurate feedback if we could also measure emotions and correlate them to what the user said. The technology was in its infancy, and Microsoft's Project Oxford was the machine learning (ML) tool that could accept a video and give us back emotions represented by numbers. We would then correlate the emotions with what they talked about in the video to determine how they felt about a specific entity.
We tested the early prototype with companies like Digicel (Jamaica) to survey users on the new cell phone data plans. We got good results that influenced how they iterated on the next plans. Our test also showed high accuracy regarding how the users really felt and what the ML models told us they felt.
We've also learned that having the user select an emoji may have similar accuracy, so we don't need the video. What we've experienced, we also found in studies from the psychology field. A simple question that accepts an emoji at the start and end of the survey can do the job. This is why the video survey market, such as VideoAsk may struggle to take off, a simple tap can do the job.
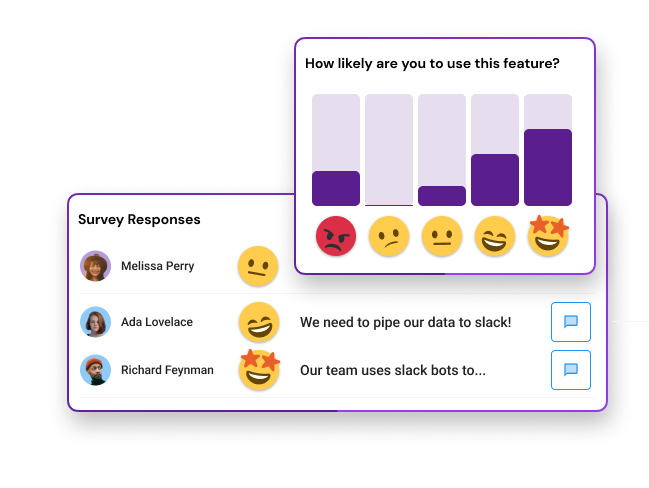
We've found that gauging human emotions can be a very strong measurement endpoint when collecting feedback. To build products, we have to understand how the products make the users feel, which can help us predict stickiness and retention. Scientists from Adobe and other organizations are doing great research in emoji analysis that correlates with what we've experienced.
👀 Chasing Observations
We took what we learned and changed the software to be embedded into websites. We added various question types and survey behaviors based on discovery calls with product managers.
We ended up in a space referred to as Microsurveys. These are small surveys embedded in the product that you can show to users based on certain interactions that you specify. Such as clicking a button or navigating to a page.
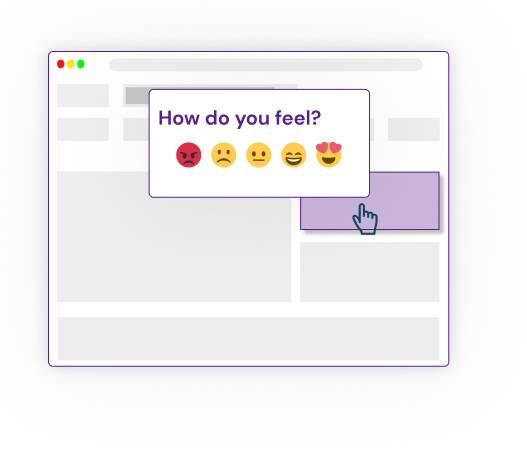
We spoke with teams using this method, and they had difficulty making sense of the survey data enough to act on it. Some combined it with their analytics stack for deeper insights. Survicate does this well by sending their survey responses to Amplitude, and their landing does a good job of explaining why you should do this.
There are many in-app survey tools on the market, like Chameleon, Sprig, or Typeform. Product Managers complained to us about how hard it is to set up these tools and have them work seamlessly with their analytics stacks, such as FullStory or Pendo.io. They complained about how fragmented the industry is, that the tooling makes their lives harder, and they'll rather stick to spreadsheets.
But even when surveys are combined with analytics tools, the teams made big guesses on data from biased human input.
Problems with Observations
When users know they are being watched, they will behave differently. Likewise, the researcher can bias the feedback by asking for answers they want to hear. These are some forms of Observer Effects.
Surveys, User Interviews, Case Studies, User Analytics are all some form of observational research that relies on biased-prone human input. Observational research is also called correlations. A good writeup on correlation vs. causation can be found here by Aishwarya Ashok and others.
So how do we know things? This is where some philosophy of science comes in. To determine if something will cause the intended effect, we must be able to falsify it, which is to run an experiment.
The medical field does "Evidence-Based Medicine," which weighs their evidence using a hierarchy of evidence. At the bottom of the pyramid are the weaker but the most abundant evidence, the observational studies. No wonder we are building bullshit. Our evidence is weak.
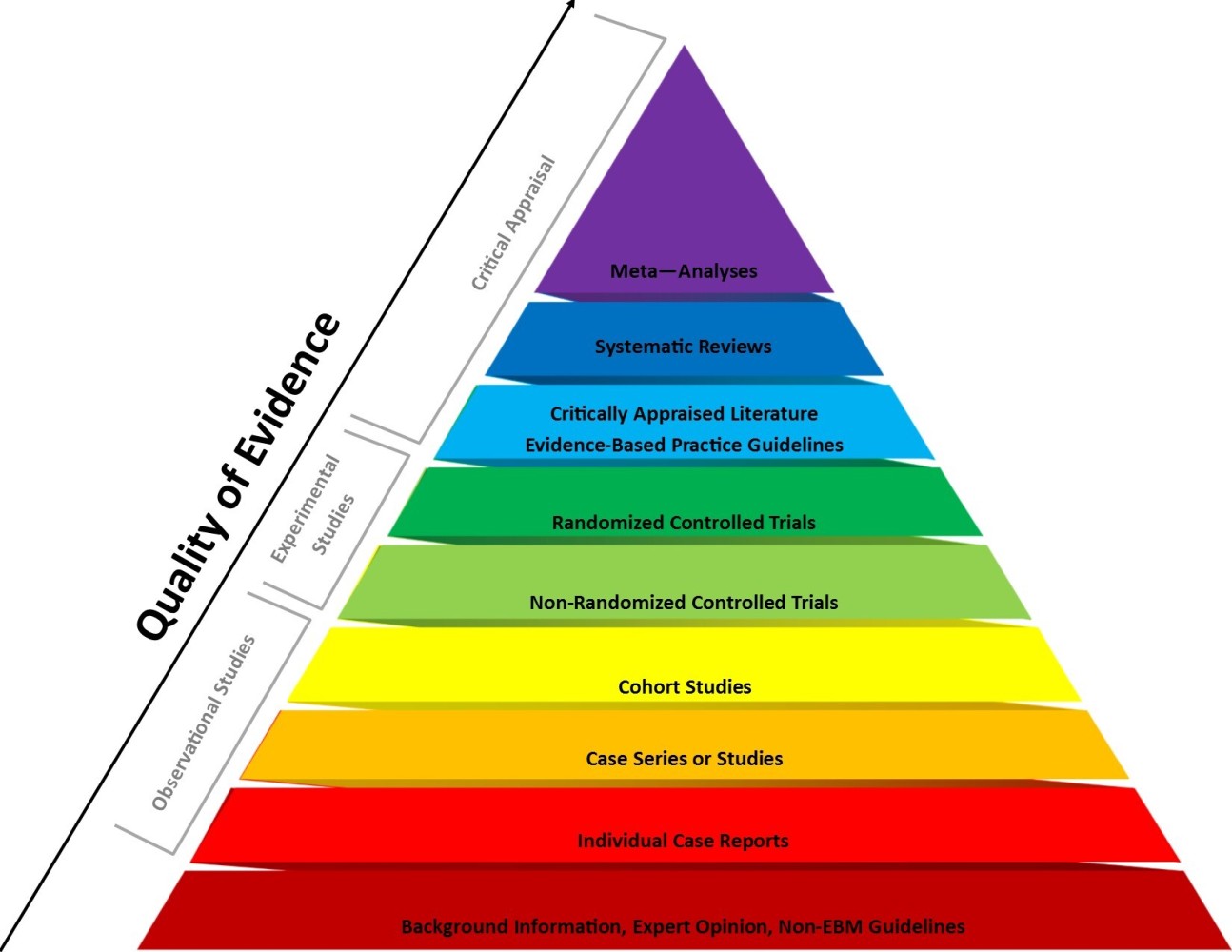
If we transform how the medical sciences weigh their evidence and apply it to Software, then it would look like this:
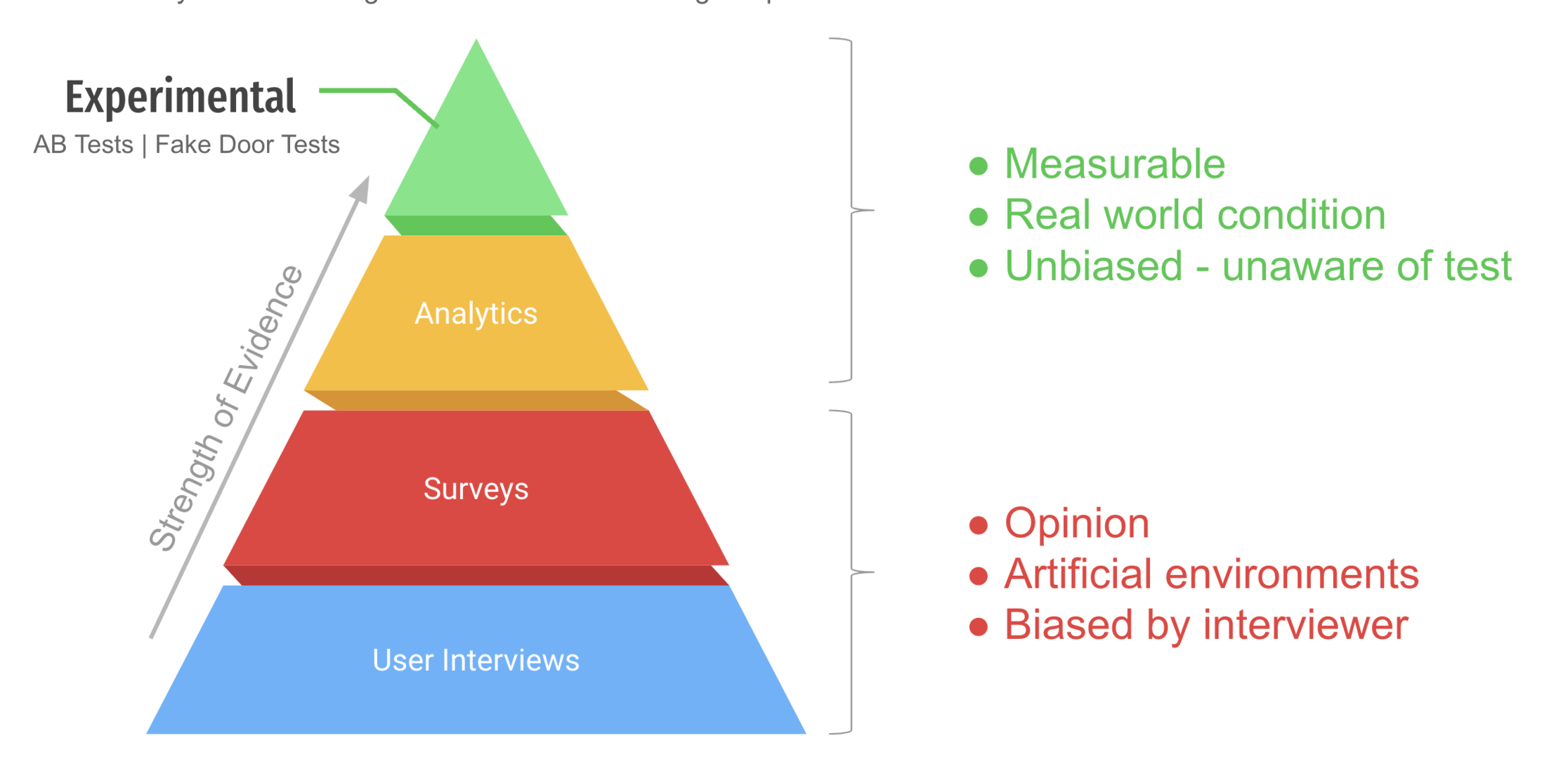
So if we are to know something, we must follow some real science, we must run experiments.
If it disagrees with experiment, it is wrong ~ Richard Feynman
Here Feynman explains very well why experiments are important.
🧪 Chasing Experiments
As we got better at interviewing Product Managers, we realized the best ones were experimental in nature and utilized tools such as AB testing to gather knowledge.
An AB test is also called a randomized controlled trial (RCT) in the clinical setting. The medical system holds RCTs as the gold standard for knowing if something caused an effect.
At the fundamental level, this is an experiment, introducing a change into a system or population and measuring what happens. We sometimes split the population into 2 groups, exposing the change to one group and a placebo to another group to account for false positives. They call this a control group, or in the AB test, it is a variant.
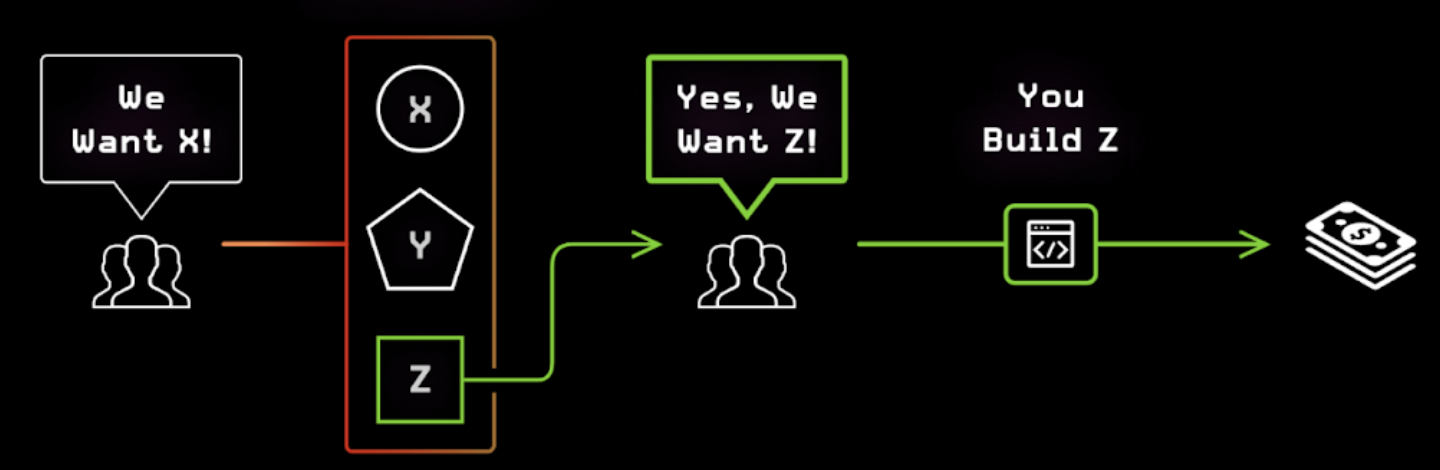
An RCT or AB Test is an experiment, also known as the "scientific method," and the philosophy goes back to Karl Popper, who wrote about falsification in the 1900s, or Aristotle, who pushed this method forward around 350 BC. It requires a drastic shift of thinking from following others to becoming your own scientist. This method is the only thing we have as a civilization that can tell what causes what.
A Minimum Viable Product (MVP) is also an experiment. You build the thing and put it in front of the user. Martin Fowler once said that nothing is better than working software in the hands of users. But an MVP requires significant cost, especially from engineers.
Problems with Experiments
When most people hear experiments, they think AB tests. But they are also very difficult to set up and understand. You'll need to learn what randomization, control groups, and statistical significance are. The tooling is not friendly for non-scientific folks looking to get into experimenting. Google Optimize, Optimizely, and other tools focus on conversion rate optimization (CRO) and not idea validation.
The teams who use AB tests for validation have invested significant resources in these tools, especially from engineers, a cost that we're trying to avoid using unless necessary. Then they have to invest in building the variants because AB testing compares whether either version A or B is moving your metric. Even feature toggle companies such as LaunchDarkly moved into experiments and offered this service very well for developers.
AB Tests are too expensive.
Think of AB testing for validation as building 2 MVPs and showing them to a group of users, then measuring to see which one is performing better. But showing a feature to one group and another feature to another group is useless for validating whether or not you should prioritize a feature. Because it is shown to 2 different sets of users, statistical significance does not apply here. The features should be tested independently so you know who really wants what.
The most fundamental origin of the control group exists to account for false positives. But this is software, not bioscience, we control the world of the user. We can account for false positives using tricks like simply collecting more information from users when they interact with a variant or making sure that the right audience is participating in the research.
There are many ways to hack an experiment and still receive sufficiently strong evidence. Our founding Engineer Nicolas Brown can attest to the hacks that game developers do with physics engines to simulate real-world physics at a fraction of the CPU and memory cost.
So do we need to build anything at all? We can validate mocks using tools like Maze, but this falls prey to observation bias. Why not validate the mock within the real user environment?
We came across something more lean and simple that gives the same quality of evidence as the scientific method that does not require full-on clinical trial levels of research involving engineers. No control group or multi-variant test is required, and no AB testing.
Fake it till you make it
Dwayne and I have been running these lean validation methods using blogs or mocks from InVision and validating demand from there. We raised our Pre-Seed round from teams like MaC Venture Capital for Samelogic, using these mocks, along with a technical proof of concept.
But there is a systematic way that the elite Product Managers are using to fail ideas fast and know with high confidence which features to build next.
Somewhere along the user journey in the product, we can introduce a mock that represents an idea or a new feature. We can then measure how many users clicked it. A conversion rate metric is also measured, a percentage of those who saw the mock and clicked it.
The conversion rate gives you a baseline signal that the feature may be needed, and you can investigate further.
Companies like Facebook do this and show some unfriendly pages like this:
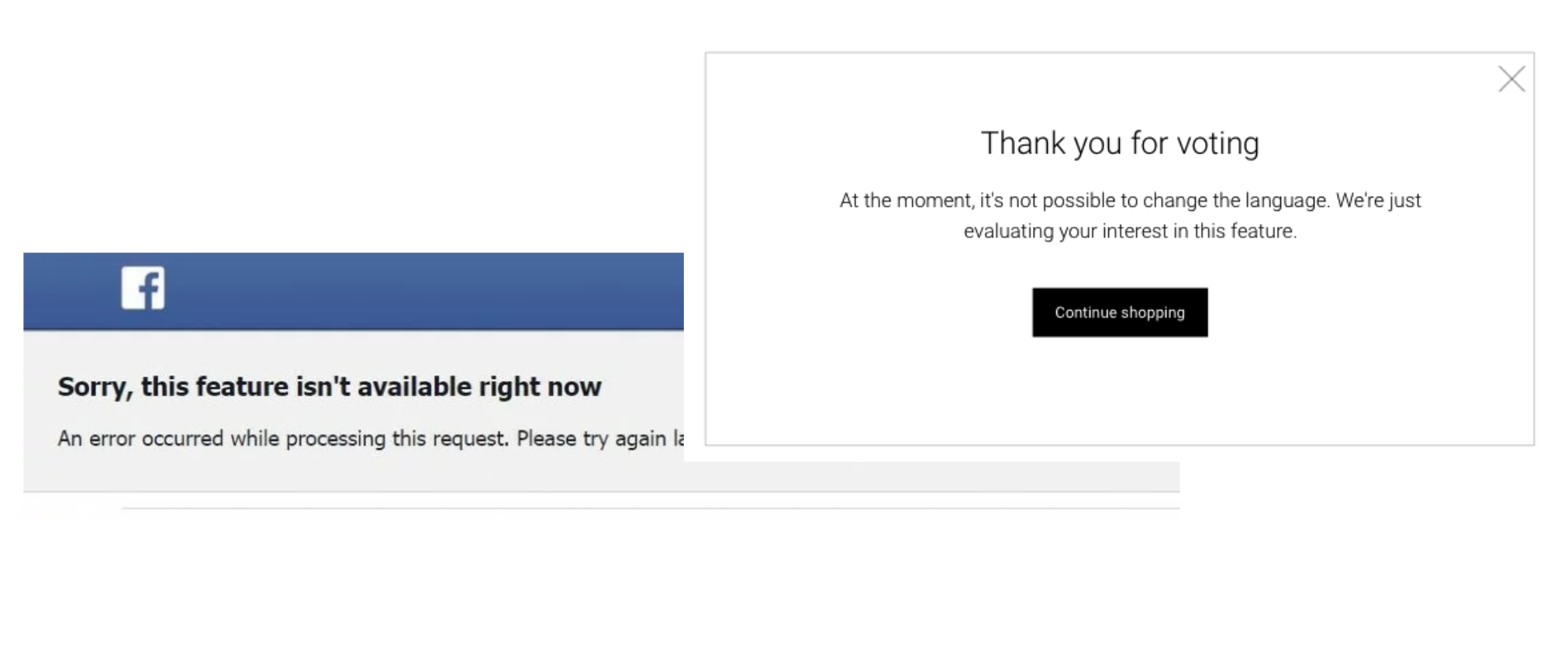
This testing method is called Fake Doors (#fakedoortests), Painted Doors, Concept Testing, Placebo Tests, or Smoke Tests.
A startup company that does this well at the very front of the funnel is Horizon by validating using ads and landing pages. They have a very good write-up on the practice here. This company even wrapped up a $1.4m pre-seed, so they know something.
This is the pinnacle of lean. We can fail at the front of the funnel before getting any serious engineering or UX work involved.
But no tool exists later down in the funnel to make this easy for the product managers with a backlog filled with ideas to validate and build. This is what we are investigating with Samelogic.
The PM should be able to drag a mock from Figma, Sketch, their Storybook design system, onto their website, expose it to a group of people and see what they are saying.
📈 Qual + Quant
Combining this fake door test with a good user experience will reduce user frustration. Showing a Microsurvey when the user interacts with the fake door has been shown to work well in our tests. People were happy to participate in the research.
So not only do we use this time to get some quantitative experimental data, we are questioning the user on why they clicked it. But more important is that we gauge human emotion during this experience.
This method gives us both experimental and observational evidence. Companies do this using in-house tools, or they have to use a combination of tools such as Segment > Engineers > Intercom.
No tool is making this easy, and that is our hypothesis of Samelogic.
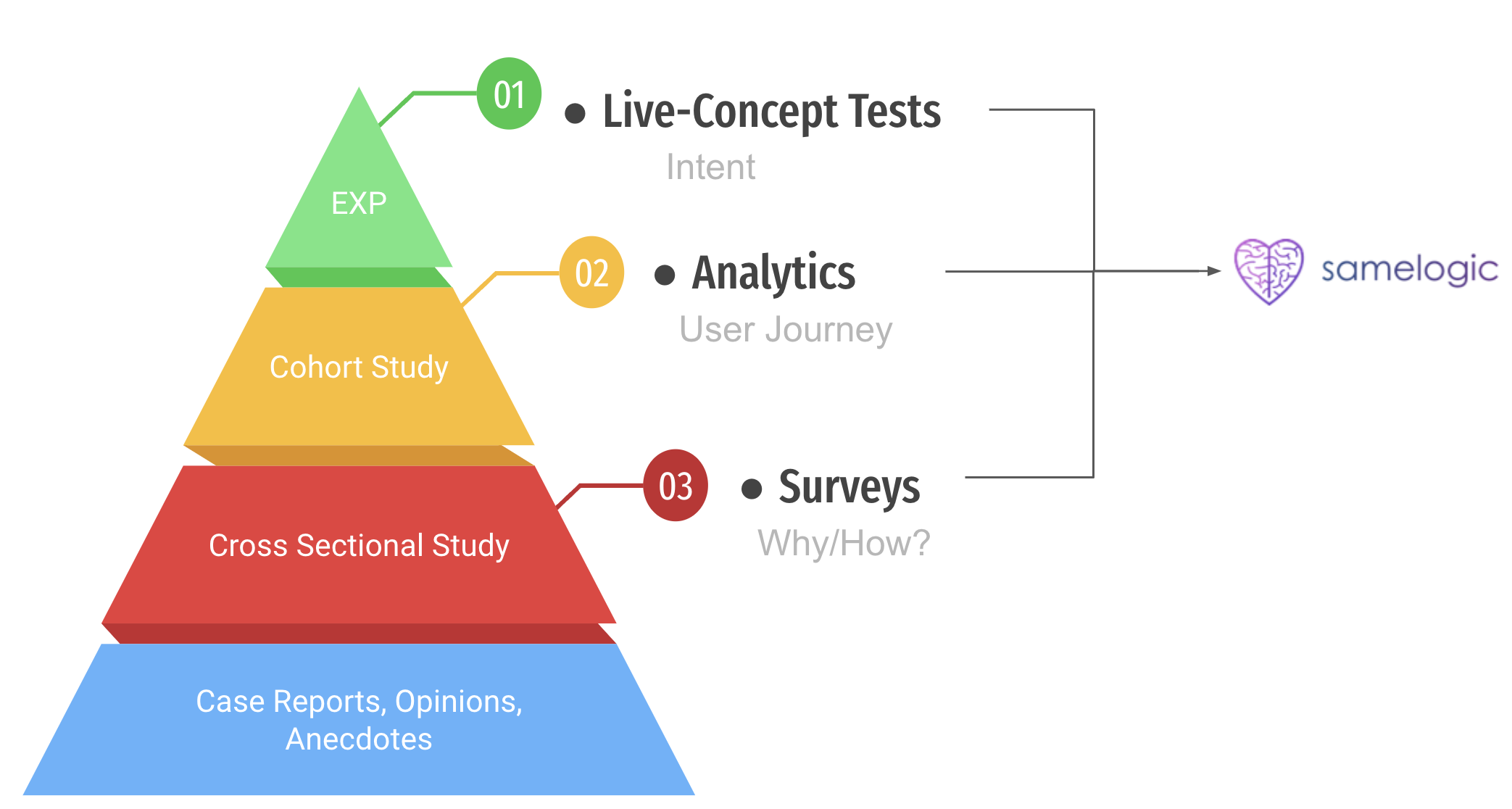
The dependency on developers must be removed for continuous idea validation using continuous experimentation to take place.
Why does this give us experimental quality evidence? It's the combination of both observational and experimental in a single test. We are running software products, not large bioscience clinical trials. We can account for false positives without the control group by combining the research methods. We are allowed to take shortcuts, that is the beauty of tech.
What needs to be answered?
As we continue investigating this space, we will publish more articles like this.
This is what our confluence doc structure looks like, and over time, we will be making all our surveys, interviews, and experiments public, including future ones.
If this Fake Door Test is so powerful, why aren't more people running them? So we set out to answer some questions:
How are others running these tests?
Why aren't more people running them? (We have a study that shows only 20% of PMs have done a fake door experiment)
Why are we writing on LinkedIn?
Our research from experimenting with Fake Door Ad Tests on LinkedIn, Facebook, and Twitter showed that LinkedIn is where our core audience is at. We have gotten a 2-4% click-through rate on LinkedIn compared to 1-2% on Facebook and Twitter. Almost all of our outreach has been on LinkedIn, so this is the funnel we are invested in.
We will primarily be dogfooding this product and process and publicly documenting what we learn to educate the other 80% and gather advice from the 20% who have done this before.
If we help companies not to build the wrong things, then we must provide evidence for the method and tool scientifically. So we are treating LinkedIn as our scientific journal where others can come and see for themselves what we are doing.
Learn about the tool
You can learn more about what we're building here: Figma + Samelogic
Follow us on LinkedIn for more articles like this and product updates.
A final note for the experts
For the people who know about fake door tests and are not running these experiments because others are telling you the user experience will be poor, test it for yourselves. Remember that what they say is observational data, their situation may not apply to you, get your own evidence, and experiment more. Ping me Shawn McLean if you'd like some help.
If you have done them before, we would love to have you on our podcast to talk more about this form of experimentation. Ping either Dwayne Samuels or Steven Samuels to get your experiences heard, and we would love to also write about it here as case studies.
Related workflows
Move from editorial context into the selector, Playwright, and bug-reproduction pages that turn exact UI evidence into action.